MHPR Algorithm Adjusted For Men's Game!
So using the data you sent, I was able to do some analysis of men's results. The way I do this is that I look at teams that play each other twice in the same year, and see how the results of the first match inform the outcome of the second. From the data, I have been able to create a list of about 5000 "match pairs," which are pairs of matches played by the same teams in the same season.
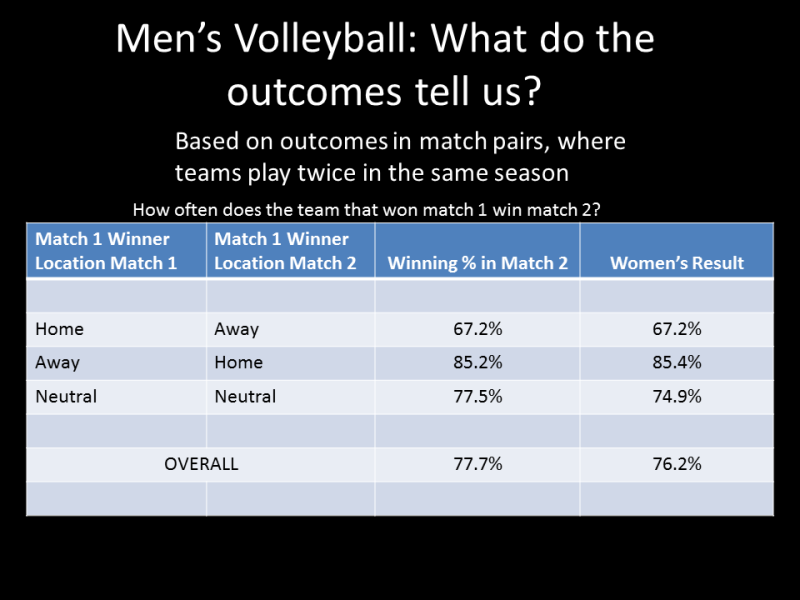
The first graphic (above) just looks at how often the team that wins the first match wins the second. As you can see, a team that wins a match has about a 75% chance of winning if they play again. That's pretty typical for volleyball. I haven't done this with a lot of sports, but one that I have done is NFL football, and there, the chance of the team winning again is only something like 62%. What that means is that the outcome of a volleyball match tells us a lot more about the relative strengths of teams compared to football. In all of this, keep in mind that a completely random outcome would be 50%.
The chance of winning in the second match does depend on the circumstances. For example, if the home team wins the first match, the chance they win the second if it is on the road is a lot lower. Similarly, if the road team wins the first match, their chance of winning if they play at home is a lot higher. In principle, the neutral/neutral pairs should be independent of the HCA. One nice thing we see in this analysis is that the overall results tend to mirror the neutral/neutral data.
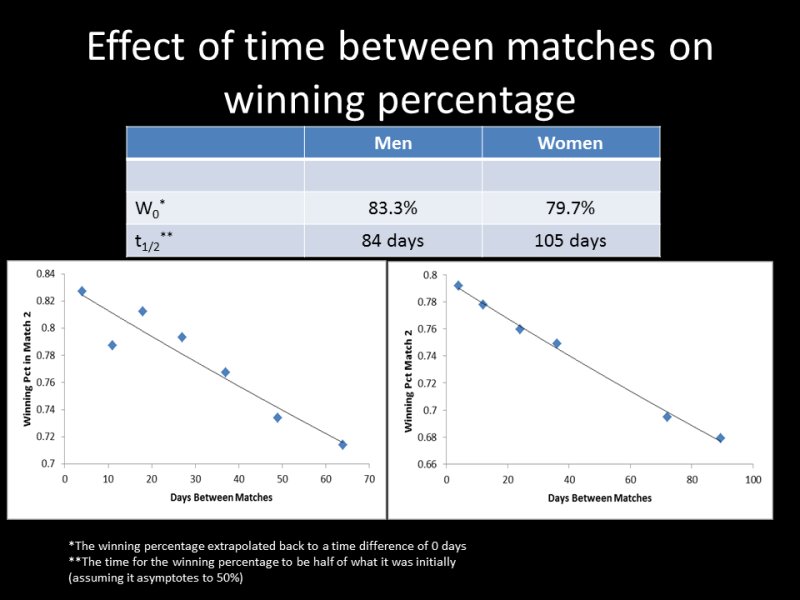
The second graphic (above) shows the effect of time. The longer between matches, the lower the winning percentage in the second match. This is the data that I use to determine the time effect on ratings and how to weight older match’s vs more recent matches. So consider that 77.5% for the overall winning percentage. We need to keep in mind that is also a function of the time difference between matches - the average time difference between match pairs is something like a month. However, by using the time dependence data, we can extrapolate back to t = 0, and we learn that if the matches were all played on the same day, the team that won the first match would win about 84% of the second matches, not 77.5%. That's interesting, because it tells us that winning basically means an 84% chance of winning (not 100%). Also, it tells us that the winning percentage drops to 50% with a "half-life" of about 12 weeks. So if a team has an 84% chance of winning the second match on day 0, it will have a 67% chance of winning a second match 12 weeks later. And if they'd play again in 12 more weeks, it would be down to 58%.
This is overall similar to what I find for the women's side, except that's a little more complicated. The women's data drop slowly for most of the season but then drops precipitously come November. However, for the men's side, there is no sign of that type of behavior, and it steadily decays as a function of time. I should note this is VERY different to the NFL, where the half-life is only about 28 days. That actually accounts a lot for why the winning percentage of the second match is so low in the NFL - because the significance of the games falls off so fast, the winning percentage is lower for the same average time between events. Basically, what it tells us is that NFL rankings are far more dependent on what you did last week.
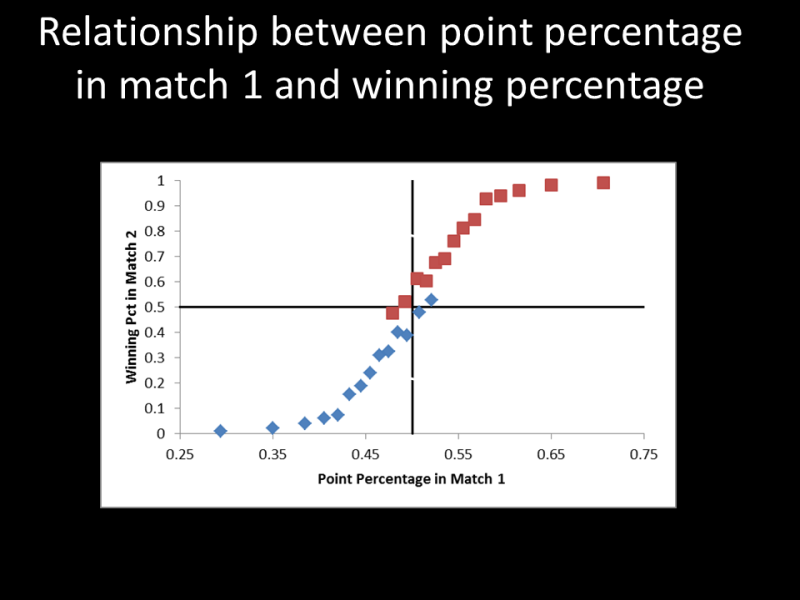
However, this is all based on just looking at who won. A more precise assessment can be made by looking at the margin of victory. The third graphic (above) shows a plot of the winning percentage in the second match as a function of the point percentage in the first. This is the whole fundamental premise of Pablo, and the data bear it out. There is a clear relationship. It's interesting; there is a difference between the results for the winning team vs the losing team. This reflects the "premium" that comes with winning. Indeed, teams that win have a little better chance of winning in the second match than would be expected based solely on their point percentage. I discovered this effect a couple years ago on the women's side. Although there is a premium on winning, the most important lesson is that it is not near as much as you might expect. It's just a couple of percent in terms of winning percentage. IOW, for teams that have a 50% point percentage will have a 55% chance of winning instead of just 50%.
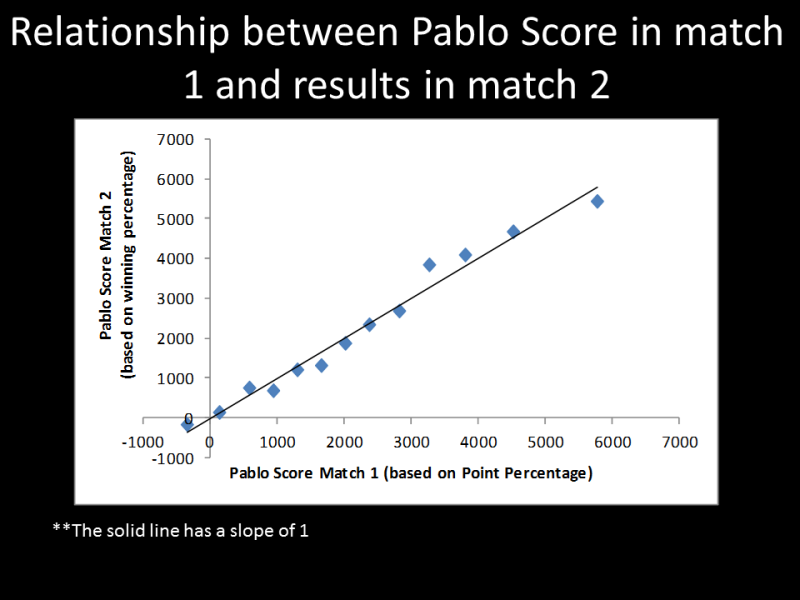
The last page shows that Pablo works on the men's side. It shows the Pablo rating difference between teams based on the point percentage in the first match vs the Pablo rating that would result based on the winning percentage of the second match. If Pablo is right, this plot should be linear, and sure enough, that's what we get. I can't understate the significance of this, because keep in mind, those two parameters, point percentage in match 1 and winning % of the population in match 2, are not related to each other in any way, except for the fact that they both reflect the qualities of the two teams.
Now, the plot I am showing has some scaling and linear scale correction factors applied. Therefore, they take into account the winning premium, and the scaling factors are set to make the slope = 1. However, this is how I use these data - to determine those terms. In the past, I have just used parameters that I determined for the women's side. Starting now, I am going to use the results of this analysis. In terms of the rankings themselves, it won't make much difference. However, the astute reader may notice that the absolute ratings are going to change, and that the top rated teams will be rated higher, and the bottom teams will be rated lower.
If anyone asks, you can tell that it comes as an effect of revising the model based on the outcomes of men's matches as opposed to women's.